지도 학습 모델 - 의사결정나무(Decision Tree)
의사결정나무(Decision Tree)
단순한 기준으로 상황을 나누어 논리적인 판단을 도출하는 알고리즘입니다. 정보 이론(information theory)를 기반으로 알고리즘을 학습합니다. 의사 결정 나무의 장점은 다양한 것이 있습니다. 결과를 해석하고 이해하기 쉬우며, 정규화 등 특징을 가공할 필요가 없습니다. 또한, 수치 자료형과 범주형 자료형을 모두 다룰 수 있습니다. 사람과 생각하는 방법이 비슷하기에, 굉장히 논리적이라고 말할 수 있습니다.
트리 구조(Tree Data Structure)
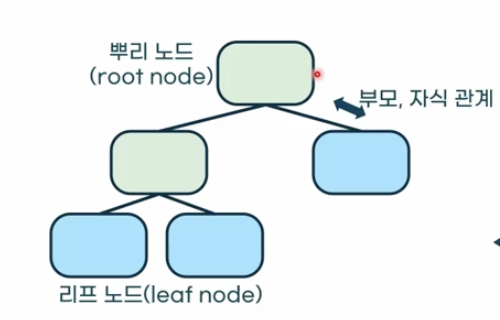
노드(node)와 간선(edge)로 이루어진 자료구조를 의미합니다. 연결된 두 노드 중 뿌리 노드에 가까운 노드를 부모 노드라고하고, 다른 노드를 자식 노드(child node)라고 합니다.
- 뿌리 노드(root node) : 트리 구조에서 최상단에 위치한 노드를 의미합니다.
- 잎새 노드(leaf node) : 자식을 가지지 않는 노드입니다.
- 내부 노드(internal node) : 잎새가 아닌 노드입니다.
의사결정나무의 학습
의사결정나무의 학습 기준
정보 이득(information gain ; IG)를 최대로 하는 것을 기준으로 설정합니다. 잎새 노드의 불순도(impurity)를 최소화하는 것이 최종 목표입니다. 대표적인 불순도 지표로는 지니 불순도, 엔트로피, 분류 오차 등이 있습니다.
가지치기(pruning)
의사결정나무의 학습이 완료된 후, 불필요한 노드를 제거하는 것을 의미합니다. 의사결정나무의 과대적합(overfitting)을 방지하기 위해서 시행됩니다. 사이킷런에서는 최소 비용- 복잡도 가지치기(minimal cost-complexity pruning)으로 구현됩니다.
회귀 트리(Regression Tree)
회귀 분석을 위한 의사 결정 나무입니다. 불순도 대신 잎새 노드에서 잔차의 변동(분산)을 최소화합니다. 잔차제곱(squared residual)이 유의미하게 향상되는지를 기준으로 가지치기를 수행합니다.